Testing intrusion detection systems is a difficult task. The main problem is that there is no consensus on how testing should be performed. What we want is a quantitative measure that we can use when performing acquisitions, when analyzing efficiency of existing solutions and for research in order to say whether a new idea is actually better than existing solutions.
Things we can measure and challenges
There are a lot of things we can measure with different levels of accuracy:
Additional challenges
Some attacks are specific to rare software, and only for particular versions of the software. We have different requirements for testing misuse and anomaly based systems because they try to solve different problems. The same goes for differences between host based and network based. They have access to very different sources of decision material. Access to good test sets is sparse and often old (outdated). The main reason is that real life data must be sanitized (very difficult) and cannot be fully controlled (be sure we know of every attack), and simulation is very time consuming. An offline test is easy to repeat, but this approach might not work for host based systems because they use a variety of different system inputs. Other aspects include what background noise to include. None, real traffic, sanitized or simulated.
What we measure
Because of all the trouble making these measurements, we tend to fall back to true and false positive rates. What we want to know is the probability of intrusion, given that an alert is generated. We use the Bayesian rule to find it.

The reason why we keep the P(I) term is that we want to know how the probability of intrusion in general affects the probability of a generated alarm being an intrusion. When the probability of attack is low, the assumption is that the error rates stay constant and the effect is that generated alarms more often will be false. This is called the base rate fallacy and is caused by a huge gap between two possible outcomes. A reduction of 99% of a huge number is still a huge number.
Another way to measure performance is the Receiver Operating Characteristics (ROC) curve. It plots the true versus the false positive rate
for a given configuration. It's good for setting the trade of between the two measures if some third variable can be adjusted.
Test data sets
The KDD cup 1999 was mentioned: a military network simulation. Used for data mining and consists of training and test data. Has many different attacks including DoS, remote to local, user to root and probing attacks. Many of the features included are very spesiffic. By now the dataset is outdated. The data-set has also been heavily criticized.
PESIM 2005 is a German data-set, but it's not publicly available because it probably contains personal sensitive data. It's simulated in virtual machines. HTTP, FTP, SMTP services using windows and Linux machines.
Things we can measure and challenges
There are a lot of things we can measure with different levels of accuracy:
- Coverage: What we get if we imagine we could know the percentage of attacks a solution can find divided by "all possible attacks" given ideal conditions like when we have no legit traffic (no "noise"). For misuse systems this is usually operationalized to mapping rules to common naming schemes (attack databases like CVE). For anomaly based systems this definition is improbable to even calculate.
Many different ways to create a rule to detect an attack. Rules can be too simple or too complex and thus be circumvented. Different networks also give attacks different weights and thus we get specialized IDS for different operating environments. - Ability to detect new attacks: When a new attack vector is released, does the IDS trigger on it?
Anomaly based systems don't have any means to detect things it does not have a rule for. Anomaly based might trigger if the chosen features makes the new attack stand out. - Probability of false alarm: Number of false positives (alarms) divided by all alarms (or by all non-intrusions..?)
IDS configurations have huge variation, and number number of false positive classifications will vary depending on configuration in addition to the factor originating from imprecise rules. - Probability of detection: Ratio of true positives (alarms) compared to number of actual intrusions.
Problem is this number depends greatly on the types of attacks used when testing, just like for antivirus solutions. Many tricks can be used for evading a NIDS (network IDS) like fragmentation, data encoding, enciphering and usage of multiple attack sources) - Resistance to circumvention attacks: Measures against sending non-attack packets that triggers many signatures with goal of overwhelming human operator or sending attack packages intended as decoys for hiding a real attack.
- Handle high volume traffic (capacity): A NIDS dropping packets will not be able to detect attacks even if it is able (has coverage). This is therefore a very important measurement, and basically how fast the IDS is.
- Performance at correlation of events: Usually not implemented in IDS at all, but instead in separate applications that aggregate logs from different sources including IDS.
IDS with less processing of packet content and less usage of state (memory use) will be faster, but then probably also score lower on detection rate and/or new unseen attacks. - Determination of success of attack: Were the target vulnerable to the run attack? Did the attack work?
Many IDS don't gather evidence regarding the success of a discovered attack, and in some instances it's not even possible to determine passively (like an attack that just kills the computer).
Additional challenges
Some attacks are specific to rare software, and only for particular versions of the software. We have different requirements for testing misuse and anomaly based systems because they try to solve different problems. The same goes for differences between host based and network based. They have access to very different sources of decision material. Access to good test sets is sparse and often old (outdated). The main reason is that real life data must be sanitized (very difficult) and cannot be fully controlled (be sure we know of every attack), and simulation is very time consuming. An offline test is easy to repeat, but this approach might not work for host based systems because they use a variety of different system inputs. Other aspects include what background noise to include. None, real traffic, sanitized or simulated.
What we measure
Because of all the trouble making these measurements, we tend to fall back to true and false positive rates. What we want to know is the probability of intrusion, given that an alert is generated. We use the Bayesian rule to find it.
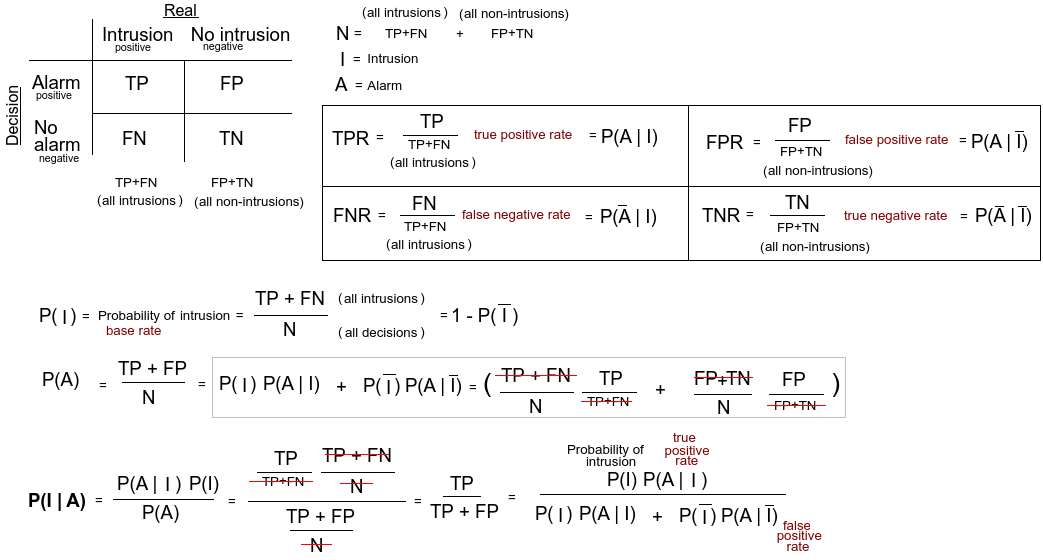
The reason why we keep the P(I) term is that we want to know how the probability of intrusion in general affects the probability of a generated alarm being an intrusion. When the probability of attack is low, the assumption is that the error rates stay constant and the effect is that generated alarms more often will be false. This is called the base rate fallacy and is caused by a huge gap between two possible outcomes. A reduction of 99% of a huge number is still a huge number.
Another way to measure performance is the Receiver Operating Characteristics (ROC) curve. It plots the true versus the false positive rate
for a given configuration. It's good for setting the trade of between the two measures if some third variable can be adjusted.
Test data sets
The KDD cup 1999 was mentioned: a military network simulation. Used for data mining and consists of training and test data. Has many different attacks including DoS, remote to local, user to root and probing attacks. Many of the features included are very spesiffic. By now the dataset is outdated. The data-set has also been heavily criticized.
PESIM 2005 is a German data-set, but it's not publicly available because it probably contains personal sensitive data. It's simulated in virtual machines. HTTP, FTP, SMTP services using windows and Linux machines.