As a small side project me and Theron made a web based price calculator for determining the price and about of ingredients are required in order to make all sorts of artisan equipment. We made a web interface and API in order to register the base cost of materials, usually based on the amount of time it would take to gather the items. Then we made a concept of a recipe in order to combine base materials into higher order materials or items. I made the backend and Theron made the graphical interface where people could place orders and read out the price in gold we would take for the trade. These images are from the internal backend components.

The sourcecode is up at https://github.com/AndyNor/andynor/tree/master/conan
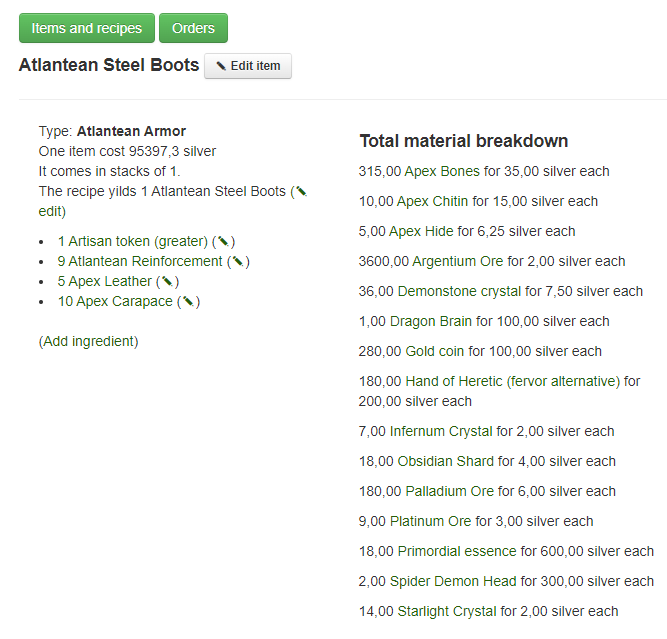
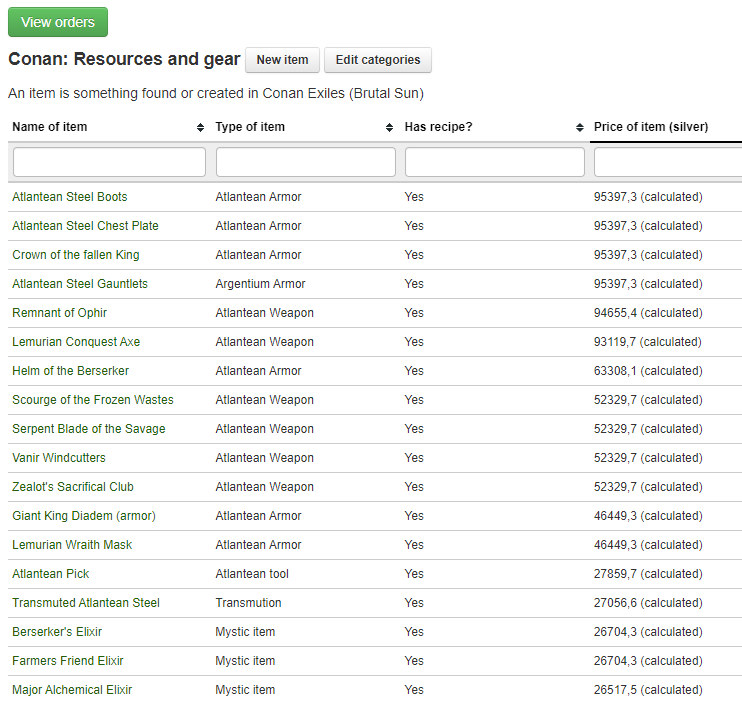
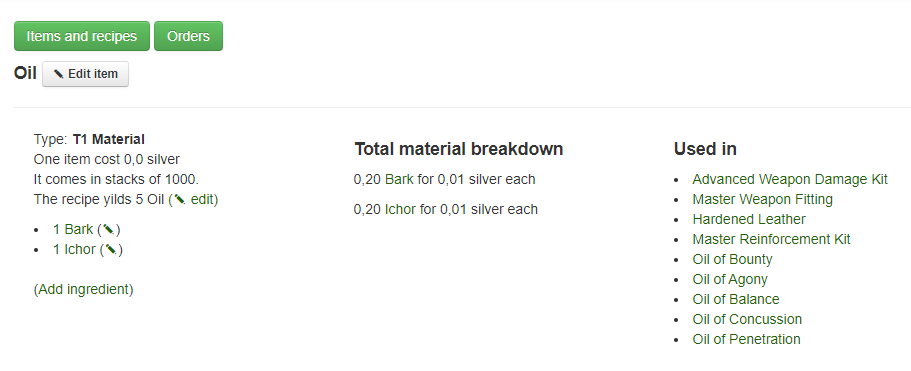
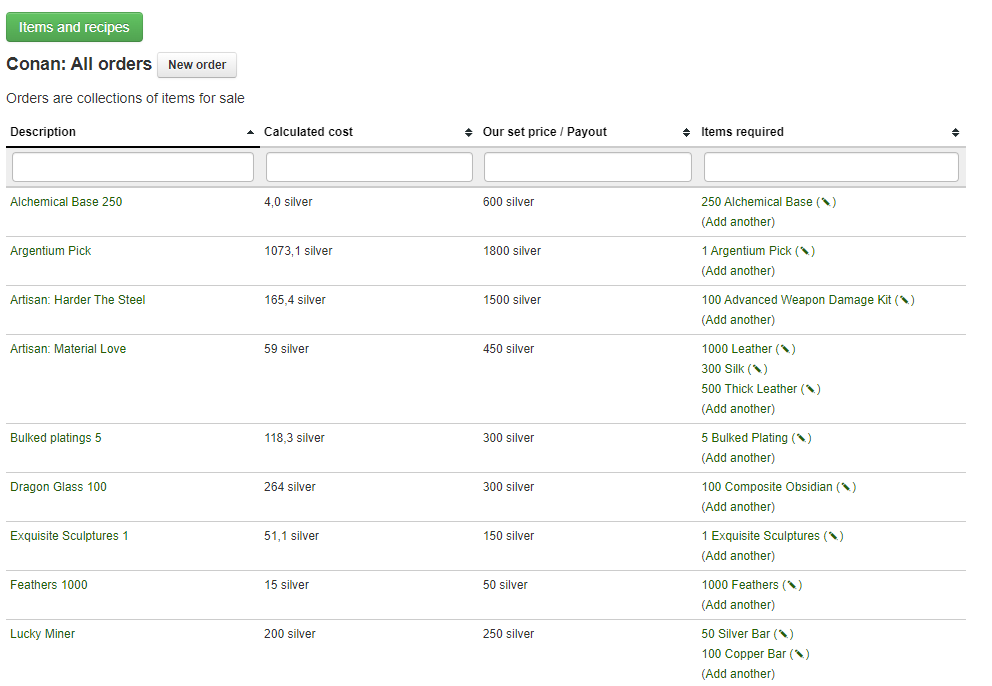
The sourcecode is up at https://github.com/AndyNor/andynor/tree/master/conan