IDS lecture 2
28 aug. 2013This lecture were the first part of misuse-based IDS where we will cover Snort, Bro and Suricata - all open source software solutions.
Misuse-based means we try to define patterns/evidence/signatures/traces of intrusions and search for these in the sensor data we collect (like network packages or logs). It's a simple concept and thus the most commonly seen method. Software solutions are slow, but good for learning. NIDS = Network Intrusion Detection System.
Snort
Snort is a famous open source IDS and IPS when combined with IP-tables (Snort inline). The speed is claimed to handle about 200-500 mbps on a regular computer and it can be optimized for speed or memory usage. Rules are written in text files and it's easy to edit or create new rules. It's originally build around pcap, a unix library for capturing packets. Later versions now use DAQ (Data AcQuisition library) and creates an abstraction layer between snort and the hardware.

The packet decoder extracts the header elements and the payload and makes it available in an optimized format. It supports a set of root protocols like Ethernet, PPP and VLAN. Inside a set of chain decoders like IPv4, IPv6, UDP, TCP, ARP, ICMP etc are activated dependent on what is received.
Pre-processing is divided in 3 categories:
- Data normalization: defragmentation (frag) (reassembly of fragmented packages), fix small discrepancies in protocol implementations, assemble TCP segments (stream). Basically avoidance of "bad strings" being hidden between end and start of another package. Inspection of application layer protocols like HTTP, FTP, SMTP etc. are performed here. Canonicalization by converting to ASCII.
- Attack detection: Port scanning detection by using a time window to keep track of ports being probed. It has support for normal one-one scans (vertically and horizontal), and many-one scans (distributed). Filters for known SSH, DNS and ARP attacks.
- Special pre-processing: Skipping enciphered traffic (if 2-way communication is seen enciphered), anonymization of data (remove "PII"), performance monitoring.
The detection module does exact string matching using an algorithm called Aho–Corasick. It's optimized for finding multiple patterns fast while having worst case and average speed very similar (Skip algorithms like Wu-Manber are unsuitable because of this). It does so by precomputing lookup tables for every rule used in finite state machines.
I implemented the algorithm in python, with some minor changes. See the Aho–Corasick page for the code.
- It finds substrings like "bcd" in "abcdef" (subsequences like "bce" in "abcdef" is not found)
- This form is called non-deterministic finite automaton (NFA)
- The algorithm can be optimized for speed, using more memory by ensuring only one next state per input symbol. This form is called DFA (deterministic). In DFA both the fail and goto functions are replaced by a δ (delta) more space hungry "next move" function. Speed optimization up to 50% in best case.
- Another optimization is called "banded-row format" [1] and works by converting something like this 00000123450000 to a combined (bandwidth, startindex, data) format. Bandwidth is the number of elements between the first and last non-zero (false) symbols: 5 in this case. Index is the location of the first non-zero item: 6 and then the following elements until the last non-zero: (5,6,1,2,3,4,5). Works on sparse data. Can be indexed by [wanted index - index + 3] and bound check must be implemented. It is unclear that the bandwidth is used for since any access to non-existing index should return 0.
- Aho-Corasick searches for multiple words at the same time, but for every rule, Snort has to redo the search and that makes it slower the more rules you got.
Logging and alerting:
The goal of logging and alerting is naturally to keep important data for later human overview and notifying about attacks, and it's very important to avoid jeopardizing performance. Snort does therefore support many output formats and outsources the job of displaying and handling the alerts. Event correlation is performed using dedicated software. Snort is not multi-threaded and thus saves a lot of time not having to wait for network I/O or similar activities. Some examples mentioned are SWATCH, BASE (old ACID) and other "Security Information Event Managers" (SIEM's) like Prelude. They might have a web interface and controls for searching, building queries and doing filtering.
Snort supports these output methods:
- TCP dump
- Syslog (typically used by firewalls and routers)
- Relational database formats like MySQL, PostgreSQL, Oracle etc.
- Unified 1 and 2 (very fast, Barnyard)
- Prelude (Universal "Security Information Event Management" (SIEM) system format)
- Aruba action (support with some wireless..)
Snort has 4 prioritization levels: high, medium, low and very low. The "classtype" (category of similar attacks) of snort rules are linked with a priority level and defined in "classification.conf". Priority can be overwritten in the rule by adding "priority <1-4>".
Snort rules
Rules consists of header and option. The header contains action (alert, log, pass, drop, reject, activate, sdrop), and triggers like protocols (TCP/UDP), ports and IP-addresses (source and destination). Variables are defined in the file snort.conf like HOME_NET and EXTERNAL_NET.
The options can be strings to search for in payload and in header content (http_uri), Snort id (sid), revision numbers, classtype (type of attack and hence priority which can be overwritten), message to display to user etc.
- msg and reference: for information only
- content, uricontent: triggers
- fragoffset, ttl etc: non-payload triggers
- logto, session: actions to perform on triggering
Example:
alert tcp $HOME_NET any -> $EXTERNAL_NET
$HTTP_PORTS (msg:"WEB-CLIENT Outlook EML
access"; flow:from_client,established; content:".eml";
http_uri; metadata:policy security-ips drop;
reference:nessus,10767; classtype:attempted-user;
sid:1233; rev:13;)
These rules are represented as a 3-dimensional rule tree in memory. First we have Rule Tree Nodes (RTN) and each of TCP, UDP, ICMP and IP has their own root with the corresponding RTN's having the same header. This is for fast filtering out rules that does not apply (TCP is not UDP). The 2nd level under RTN is OTN (OptionTN) and contains the different rules that must be checked one by one until a match is found or not. The third level "optFunctionalCode" is the actual triggers that might be shared between OTN's. Each OTN will link to all triggers they require. (For avoiding storing a compiled "state machine" more than once?)
More examples:
- WinNuke:
alert tcp $EXTERNAL_NET any -> $HOME_NET 135:139 (msg:
"DOS Winnuke attack"; flow: stateless; flags: U+;) - Netbios smb cd..:
alert tcp $EXTERNAL_NET any -> $HOME_NET 139
(msg:"NETBIOS SMB CD.."; flow:to_server,established;
content:"|5C|../|00 00 00|";) - The semicolon bug:
alert tcp $EXTERNAL_NET any -> $HOME_NET
$HTTP_PORTS (msg:"WEB-IIS multiple extension code
execution attempt"; flow:established,to_server;
content:".asp|3B|."; nocase; http_uri;)
Using it in a distributed mode
The most common setup is 3-tier, and 4-tier was mentioned. The main idea is to separate a tier (layer) for each sensors, server and console. The sensor layer consists of hardened machines with two NIC (network interface cards). One stealth without IP listening for all traffic in promiscuous mode and the other for talking with the server-layer. A firewall can be placed between these layers to protect, and in addition encryption should be used. The server tier manages updating of the sensor layer with new rules and receives logs and alerts from the sensors and running the server part of the presentation system. The 3rd tier is for clients of the presentation software like mentioned above and should connect using secure HTTP.
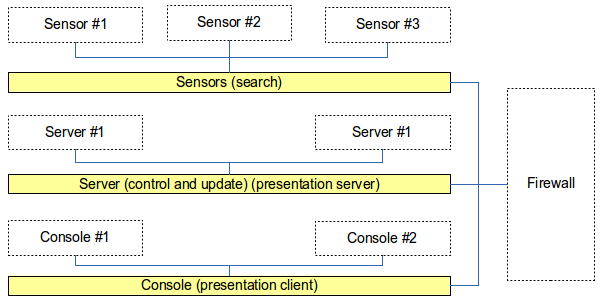
Example of Snort 3-Tier distributed setup
How to install Snort (lab)
Page on snort installation
How to configure it correctly (Post installation)
There are two main concerns: false positives and false negatives.
- False positives can be removed by adjusting the rules. All networks are different and the default rules might not apply. Like a rule for a service not in use. You can create "pass" rules (pass instead of alert in the beginning of rule). If two similar rules exist, then alert rules will have presides. Starting Snort with "snort -o" will swap this order (alert, pass, log --> pass, alert, log)
- False negatives is defined as attacks you have signatures for, but is still not found. Main reason is packet loss. Possible solutions are increasing the resources of the machine running Snort, skipping streaming traffic like media (multicast), remove traffic from "safe" ranges, skip enciphered text (one of the preprocessors), disable some TCP reassembly, set client_flow_depth, memcap's, timeouts and several other variables. Berkley packet filter can be used. Remember to set up HOME_NET and EXTERNAL_NET in snort.conf. Monitor the performance plugin preprocessor for details.
Additional lecture on DAWGs
Aho-Corasick is used in the open source IDS'es and believed to be the fastest algorithm for the job. It it slow and the question is whether using Directed Acyclic Word Graphs (DAWG's) is faster. An algorithm called "Backward Non-Deterministic DAWG matching with q-grams" (BNDMq) were presented. It also created a finite state machine by mapping all possible sub-strings of the key words being searched for. It is claimed to produce the minimum automaton and thus the lowest memory consumption. It had offline and online construction of this machine using terms like suffix links, solid and non-solid links and equivalent classes.
[1] Optimizing Pattern Matching for Intrusion Detection (Marc Norton)