DF2: Advanced File Carving
28 apr. 2013Main topics today:
- How to write a paper
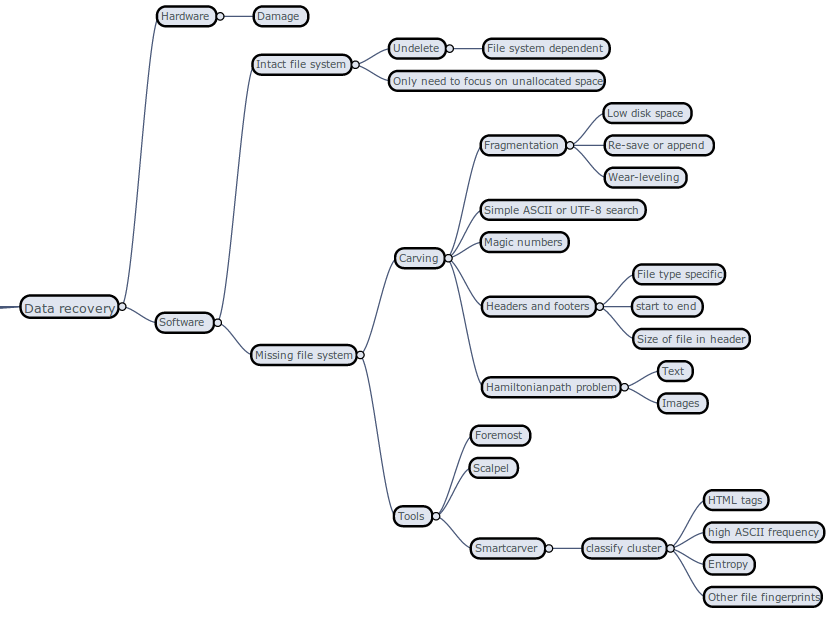
- Introduction to file carving: Look for strings, look for header and footers, how to deal with fragmentation? Try to use Foremost and Scalpel
- Review of two file carving papers in small groups, followed by presenting and discussion/questions
The two papers were "File type identification of data fragments by their binary structure" and "statistical disk cluster classification for file carving" (I'm not 100% sure of the last one..)
Basic principles in the two papers were trying to identify what type of file a small chunk of binary data belong to, using statistical/machine learning techniques, in the context of missing/destroyed file table (hence carving). Known methods like looking for headers and footers were known, but they were not sufficient for situation dealing with fragmentation. One paper looked at histograms of byte values (0-255) for chunks of data, typically 512B-4K at a time, combining it with how much individual bytes change (in value) inside the chunk, using the fact different information content will lead to different histogram patterns. The other paper used an approach more like clustering (not sure), dividing data into learn and test sets. During discussions we talked about using bigger "words" (i.e. 2 or more bytes) in order to increase chance of catching a relevant feature (n-gram's), the difference between classifier with multiple outputs vs many single classifiers specializing on finding one pattern (file type in this context, the later is preferred), and generally being skeptical of how much test result actually mean unless the methods are well understood...
Read "The Evolution of file carving - The benefits and problems of forensics recovery" for a good overview of the topic