19. september 2012 - lecture #5 (Ethics and statistical methods)
In order for the voluntary consent to be informed, the subjects need to be aware of the method and specifics of the experiment. This knowledge could change the results of the experiment, and potentially falsify the conclusion. One way to limit this effect is by using control groups where participants know what will happen, but they are randomly assigned to either the control group or the test group. Another is by using a deceptive approach (making the subject believe something different is measured. It is still important to inform of the actual goal afterwards.
There is always a cost / benefit aspect of science. The importance of the science has to be weighted against any harm (to humans and animals). Other cost of an experiment could be the subjects time and their honor (you make them do something they don't feel like or feel stupid). Another interesting aspect is when you discover things the subjects would be better off not knowing (the life lie)
Privacy: It should not be possible to trace the source (like in a questionnaire, who had this opinion). In other words anonymity. Keep information confidential and separate identity from data. Also any keys linking different data sets (like when a person has followed up on a survey). There is always the problem with small populations what one could guess who's behind with some local knowledge.
Normal everyday events follow a normal (Gaussian) distribution as shown in this java applet. One can see that a lot of samples is unnecessary to be confident a mean value is actually true because of a natural probabilistic variation. In other words, groups would overlap.
Types of data How measurable is the variable?
More statistical methods are available in the "scale" end of the types. One still need to be careful with subjective submitted data that is arranged in a scale like in "Describe your feelings for something with a number from 1-10". Even though the subject can choose between 10 distinct values, their perceived subjective opinion is not leveled between subjects. My 5 could be another persons 9, since we have different experiences we compare with.
Descriptive statistics Start by checking the distribution, find the mean (average), median (ordered middle), mode (most frequent) and range. Calculate the variance and the standard deviation. Calculate confidence interval (with a chosen significance level). Visualize to get a feeling of the data. The point is to determine how much variation is normal. Normally one would expect to have about 68% of the observations within plus/minus 1 standard deviation and about 96% within plus/minus 2 standard deviations. The significance level is the range you are x% sure the true score lies within.
Find the correlation between variables. A correlation is a value between -1 and 1. The higher the absolute value, the higher the correlation. 0 would be no correlation. Remember correlations does not imply causation.
Chi-square distribution can be used to determine how likely two data sets the same or different populations.

Normal distribution, image from wikipedia
Confidence interval: Range of values a population lies within given a required certainty. Like within 95%.
Correlation: Measure of relationship between variables, like the Pearson product-moment correlation coefficient being a number between -1 and 1. Zero would be no correlation and plus/minus one is a high degree of correlation.
Inferential statistics: Assume some characteristics about the data
In advance of this lecture every group had a talk with the teacher to clarify details of the project. By the 2nd of October every group had to deliver their data from an experiment. It was important the data had more than one dependent variable. The two coming weeks we are to work on the project, followed by two weeks for presentation, and then exam. No more official lectures in other words
Ethics
Historically ethical issues were not very dominant before world war 2. Findings were more important. The medical field was the first to see rules (Nuremberg code, 1947) as a result of the inhumane treatment of prisoners during the war. Important principles were voluntary informed consent, avoid physical and mental suffering or injury, liberty to end participation at any time during the experiment. It was followed by the declaration of Helsinki, 1964.In order for the voluntary consent to be informed, the subjects need to be aware of the method and specifics of the experiment. This knowledge could change the results of the experiment, and potentially falsify the conclusion. One way to limit this effect is by using control groups where participants know what will happen, but they are randomly assigned to either the control group or the test group. Another is by using a deceptive approach (making the subject believe something different is measured. It is still important to inform of the actual goal afterwards.
- How subjects are treated: The primary consideration has to be the welfare of the participants. The obedience studies done by Stanley Milgram is often used as an example of how people can hurt others if they are told by an authority. In this experiment, the electric shock was faked, but the mental stress of the participants was still high (they were "manipulated" to apply a lot of voltage on another person) (read the "Guidelines for research ethics in science and technology (2008)" PDF)
- Do not cheat: Don't make up data, don't hide data or unwanted findings, avoid plagiarism (cite sources you refer). Detect and notify the reader of your work of your possible biases. Be specially careful when working for an organization with economical or political motivation. (Negative results are under reported)
- Social norms: Be careful with "hot topics": Gender, religion, race etc. Like "girls are better than boys at something", and "this race is smarter than that race".. It could be true in some cases, but like when it comes to these matters, peoples feelings are so strong and when hurt could case havoc. If these variables are not studied independently, it it normal not to say anything about them.
There is always a cost / benefit aspect of science. The importance of the science has to be weighted against any harm (to humans and animals). Other cost of an experiment could be the subjects time and their honor (you make them do something they don't feel like or feel stupid). Another interesting aspect is when you discover things the subjects would be better off not knowing (the life lie)
Privacy: It should not be possible to trace the source (like in a questionnaire, who had this opinion). In other words anonymity. Keep information confidential and separate identity from data. Also any keys linking different data sets (like when a person has followed up on a survey). There is always the problem with small populations what one could guess who's behind with some local knowledge.
Statistics
A part of the methodology is to define a scientific hypothesis (H1) meaning the hypothesis (best guess of outcome) is valid. The zero hypothesis (H0) is simply hypothesis being wrong. Are you dealing with two populations (reject the H0: H1 is true) or one population (fail to reject H0: H0 is true). A population refers to the fact that a dependent variable separates different groups of test subjects, and the difference has to be significant. Significant has to be defined, but typically it has to be a measure of certainty, like 95% or 99%.Normal everyday events follow a normal (Gaussian) distribution as shown in this java applet. One can see that a lot of samples is unnecessary to be confident a mean value is actually true because of a natural probabilistic variation. In other words, groups would overlap.
- Type 1 error: Falsely accepting H1, and can be controlled by setting the significance level.
- Type 2 error: Falsely accepting H0. It would probably mean the design of the experiment was wrong, or the effect is so small it requires greater precision.
Types of data How measurable is the variable?
- Nominal: Label that cannot be ranked (like gender (people), sedimentary (rocks) and country (nationality)
- Ordinal: Greater or less than, but with little knowledge of the distance between units. Like a little, like, like a lot.
- Scale: Ranking with equal distance between units (height, temperature, speed, test score) (interval data, could also be ratio data if it has a true zero point)
More statistical methods are available in the "scale" end of the types. One still need to be careful with subjective submitted data that is arranged in a scale like in "Describe your feelings for something with a number from 1-10". Even though the subject can choose between 10 distinct values, their perceived subjective opinion is not leveled between subjects. My 5 could be another persons 9, since we have different experiences we compare with.
Descriptive statistics Start by checking the distribution, find the mean (average), median (ordered middle), mode (most frequent) and range. Calculate the variance and the standard deviation. Calculate confidence interval (with a chosen significance level). Visualize to get a feeling of the data. The point is to determine how much variation is normal. Normally one would expect to have about 68% of the observations within plus/minus 1 standard deviation and about 96% within plus/minus 2 standard deviations. The significance level is the range you are x% sure the true score lies within.
Find the correlation between variables. A correlation is a value between -1 and 1. The higher the absolute value, the higher the correlation. 0 would be no correlation. Remember correlations does not imply causation.
Chi-square distribution can be used to determine how likely two data sets the same or different populations.
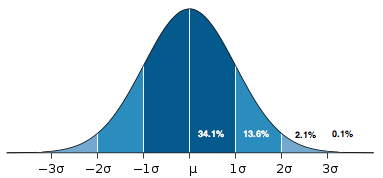
Normal distribution, image from wikipedia
Confidence interval: Range of values a population lies within given a required certainty. Like within 95%.
Correlation: Measure of relationship between variables, like the Pearson product-moment correlation coefficient being a number between -1 and 1. Zero would be no correlation and plus/minus one is a high degree of correlation.
Inferential statistics: Assume some characteristics about the data