Symbolic and statistical learning
14 feb. 2013In this lecture we touched upon some of the machine learning algorithms we have only heard of till now.
Symbolic
- Decision trees: Often binary trees because they are simpler. They have problem with overfitting, they can be pruned to get rid of irrelevant nodes)
- Regression trees: same but continuous value output instead of classification

- Association rules: The idea behind associate rules is that given a set of items that can take on a binary value (active or not) and a number of transactions that can take any combination of these items, then an associative rule is saying that the probability of choosing an item given one or more other items is high. One example of this can be seen on on-line shops like amazon where when you look at a product you get recommendations for other products that were part of a previous sale. Associate rules is basically trying combinations and finding ones with high confidence, finding correlations between variables.


Statistical
- Bayes classification - Naive Bayes: Bayes Belief Network? The naive part is the assumption that all the attributes are independent. Using Bayes theorem we get this formula:
(See this video lecture) - Discriminant functions: Linear/quadratic/general function making up the decision boundary (curve/plane/surface)
- Linear / polynomial regression
- (weighted) k nearest neighbor - Lazy learning (See k-NN algorithm by mathematicalmonk)
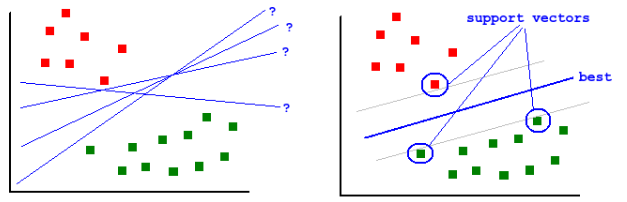
- Support vector machines (SVM): See SVM at Caltech and SVM javascript demo - turn "kernel trick" on and off. The main idea is to find the best linear separation between two classes so that the margin is maximized. The formula can be adjusted by how much it "cares for outliers". The kernel trick is to transform the original data that is not linearly seperable to another domain where they are.
- Artificial Neural Networks (See lecture 7)
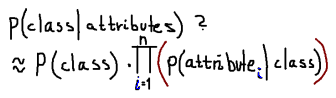

Simple k-NN implementation in python
import math
from collections import defaultdicttraining_data = [(1, 2, 2), (1, 5, 1), (1, 7, 2), (1, 7, 4), (1, 4, 3), (2, 3, 3), (2, 5, 3), (2, 6, 5), (2, 4, 7), (2, 3, 5)]
test_data = [(None, 4, 4), (None, 4, 2), (None, 6, 2)]def classify(sample, training_data, k, method):
def distance(a, b, method):
dist1 = float(a[1] - b[1])
dist2 = float(a[2] - b[2])
dist1_ = math.fabs(a[1]) + math.fabs(b[1])
dist2_ = math.fabs(a[2]) + math.fabs(b[2])
if method == "euclidean":
return math.sqrt(
math.pow(dist1, 2) + math.pow(dist2, 2)
)
if method == "city_block":
return math.fabs(dist1) + math.fabs(dist2)
if method == "manhattan_distance":
return math.fabs(dist1) + math.fabs(dist2) # it's another name for city block
if method == "canberra":
return (math.fabs(dist1) / dist1_) + (math.fabs(dist2) / dist2_)# [distance, classification]
closest = []
for example in training_data:
dist = distance(example, sample, method)
closest.append([dist, example[0]]) # distance and classification# return most dominant of k nearest
k_nearest = sorted(closest)[0:k]# http://stackoverflow.com/questions/893417/item-frequency-count-in-python
frequencies = defaultdict(int)
for item in k_nearest:
frequencies[item[1]] += 1 # count frequency of classesmost_frequent = [None, None] # empty
for key, value in frequencies.iteritems():
if value > most_frequent[1]:
most_frequent = [key, value]
return most_frequent[0]for sample in test_data:
print "\nSample: %s%s" % (sample, "") # somehow sample in it self does not convert None type correctly..
print("K=1, Euclidean, has class %s") % (classify(sample, training_data, 1, "euclidean"))
print("K=3, Euclidean, has class %s") % (classify(sample, training_data, 3, "euclidean"))
print("K=5, Euclidean, has class %s") % (classify(sample, training_data, 5, "euclidean"))
print("K=1, City Block, has class %s") % (classify(sample, training_data, 1, "city_block"))
print("K=3, City Block, has class %s") % (classify(sample, training_data, 3, "city_block"))
print("K=5, City Block, has class %s") % (classify(sample, training_data, 5, "city_block"))
print("K=1, Manhattan, has class %s") % (classify(sample, training_data, 1, "manhattan_distance"))
print("K=3, Manhattan, has class %s") % (classify(sample, training_data, 3, "manhattan_distance"))
print("K=5, Manhattan, has class %s") % (classify(sample, training_data, 5, "manhattan_distance"))
print("K=1, Canberra, has class %s") % (classify(sample, training_data, 1, "canberra"))
print("K=3, Canberra, has class %s") % (classify(sample, training_data, 3, "canberra"))
print("K=5, Canberra, has class %s") % (classify(sample, training_data, 5, "canberra"))