This method is actually much simpler and safer: use-pool.py. The previous mentioned method has some issues when too much data is fed into the queue and can cause a deadlock as discussed in this thread
A screenshot from today's work:

Notice the blue "1 process" vs the other "4/6 process executions" at the monitor left,top
Multi-threading is quite broken for CPU intensive work in Python, this according to this presentation. For my use I did not need to share memory between the workers (see multiprocessing-vs-threading) so a much better alternative is to use multiprocessing. This tutorial had exactly what I needed. A way to queue tasks (in my case usernames for a meta data extraction script) and spread the work to a given number of processes. My speed up was about 3.5x which is not that far from my actual cores being 4. Quite a nice speedup.
"Bear in mind that a process that has put items in a queue will wait
before terminating until all the buffered items are fed by the
“feeder” thread to the underlying pipe. (The child process can call
the Queue.cancel_join_thread() method of the queue to avoid this
behaviour.)
This means that whenever you use a queue you need to make sure that
all items which have been put on the queue will eventually be removed
before the process is joined. Otherwise you cannot be sure that
processes which have put items on the queue will terminate. Remember
also that non-daemonic processes will be automatically be joined."
A screenshot from today's work:
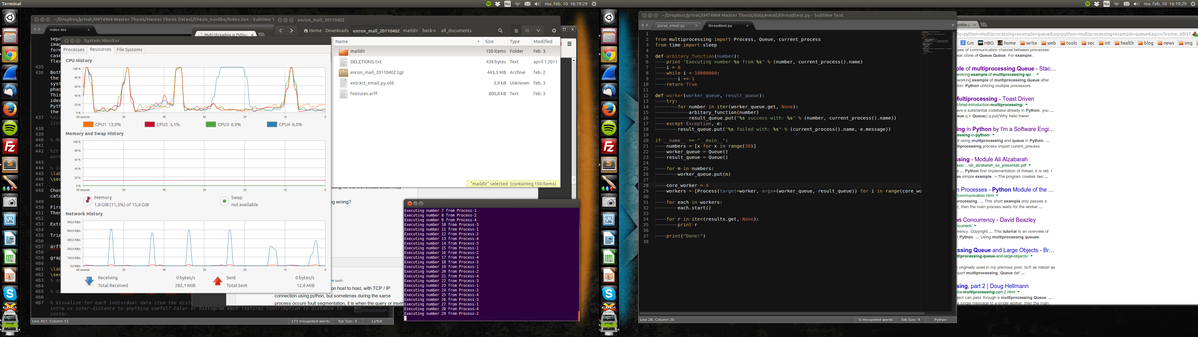
Notice the blue "1 process" vs the other "4/6 process executions" at the monitor left,top
Multi-threading is quite broken for CPU intensive work in Python, this according to this presentation. For my use I did not need to share memory between the workers (see multiprocessing-vs-threading) so a much better alternative is to use multiprocessing. This tutorial had exactly what I needed. A way to queue tasks (in my case usernames for a meta data extraction script) and spread the work to a given number of processes. My speed up was about 3.5x which is not that far from my actual cores being 4. Quite a nice speedup.