In a previous post (Crawling for music) I tried to automate the process of importing the soundtracks played in the Freakonomics podcast via their tags in the audio transcripts. Some time has passed, new songs have been added and my script required some maintenance. These are the new Python scripts:
Removed a lot of unnecessary code and keep track of previously visited pages in order to avoid looking up a page over and over again.
Still using ivyishere.org though. Perhaps I'll look into using the Spotify API directly later...
 freakocrawl
freakocrawl raw_music_tags
raw_music_tagsRemoved a lot of unnecessary code and keep track of previously visited pages in order to avoid looking up a page over and over again.
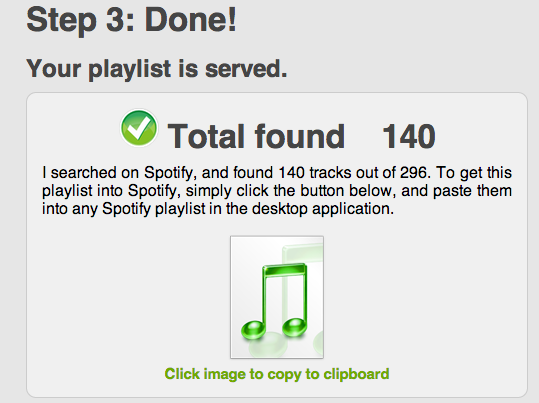
 Of the 296 unique songs found so far, 140 was found on Spotify (compared to 60 last run)
Of the 296 unique songs found so far, 140 was found on Spotify (compared to 60 last run)- All tags gathered so far in raw format
- After a lot of regex manipulation
- On the clipboard after using the ivy service. Use "spotify_check.py" for finding the difference between two such listings.

Still using ivyishere.org though. Perhaps I'll look into using the Spotify API directly later...
The spotify playlist links:
Spotify-link: spotify:user:andynor:playlist:6BvaERimeLjzciEshOxsNX
HTTP-link: open.spotify.com/user/andynor/playlist/6BvaERimeLjzciEshOxsNX
Spotify-link: spotify:user:andynor:playlist:6BvaERimeLjzciEshOxsNX
HTTP-link: open.spotify.com/user/andynor/playlist/6BvaERimeLjzciEshOxsNX